
How to Choose GPUs for Deep Learning and Large Language Models
When selecting GPUs for deep learning workloads, especially for training and running large language models (LLMs), several factors need consideration. Here's a comprehensive guide to making the right choice.
Table: Latest Leading Open Source LLMs and Their GPU Requirements for Local Deployment
| Model | Parameters | VRAM Requirement | Recommended GPU |
|---|---|---|---|
| DeepSeek R1 | 671B | ~1,342GB | NVIDIA A100 80GB ×16 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~0.7GB | NVIDIA RTX 3060 12GB+ |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~3.3GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~3.7GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~6.5GB | NVIDIA RTX 3080 10GB+ |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~14.9GB | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~32.7GB | NVIDIA RTX 4090 24GB ×2 |
| Llama 3 70B | 70B | ~140GB (estimated) | NVIDIA 3000 series, 32GB RAM minimum |
| Llama 3.3 (smaller models) | Varies | At least 12GB VRAM | NVIDIA RTX 3000 series |
| Llama 3.3 (larger models) | Varies | At least 24GB VRAM | NVIDIA RTX 3000 series |
| GPT-NeoX | 20B | 48GB+ VRAM total | Two NVIDIA RTX 3090s (24GB each) |
| BLOOM | 176B | 40GB+ VRAM for training | NVIDIA A100 or H100 |
Key Considerations When Choosing GPUs
1. Memory Requirements
- VRAM Capacity: Perhaps the most critical factor for LLMs. Larger models require more memory to store parameters, gradients, optimizer states, and cached training samples.
** Table: Importance of VRAM in Large Language Models (LLMs).**
| Aspect | Role of VRAM | Why It’s Crucial | Impact if Insufficient |
|---|---|---|---|
| Model Storage | Holds model weights and layers | Required for efficient processing | Offloads to slower memory; major performance drop |
| Intermediate Computation | Stores activations and intermediate data | Enables real-time forward/backward passes | Limits parallelism and increases latency |
| Batch Processing | Supports larger batch sizes | Improves throughput and speed | Smaller batches; slower training/inference |
| Parallelism Support | Enables model/data parallelism across GPUs | Necessary for very large models (e.g., GPT-4) | Limits scalability across multiple GPUs |
| Memory Bandwidth | Provides high-speed data access | Accelerates tensor operations like matrix multiplications | Bottlenecks in compute-heavy tasks |
- Calculate Your Needs: You can estimate memory requirements based on your model size and batch size.
- Memory Bandwidth: Higher bandwidth allows faster data transfer between GPU memory and processing cores.
2. Computing Power
- CUDA Cores: More cores generally mean faster parallel processing.
- Tensor Cores: Specialized for matrix operations, crucial for deep learning tasks.
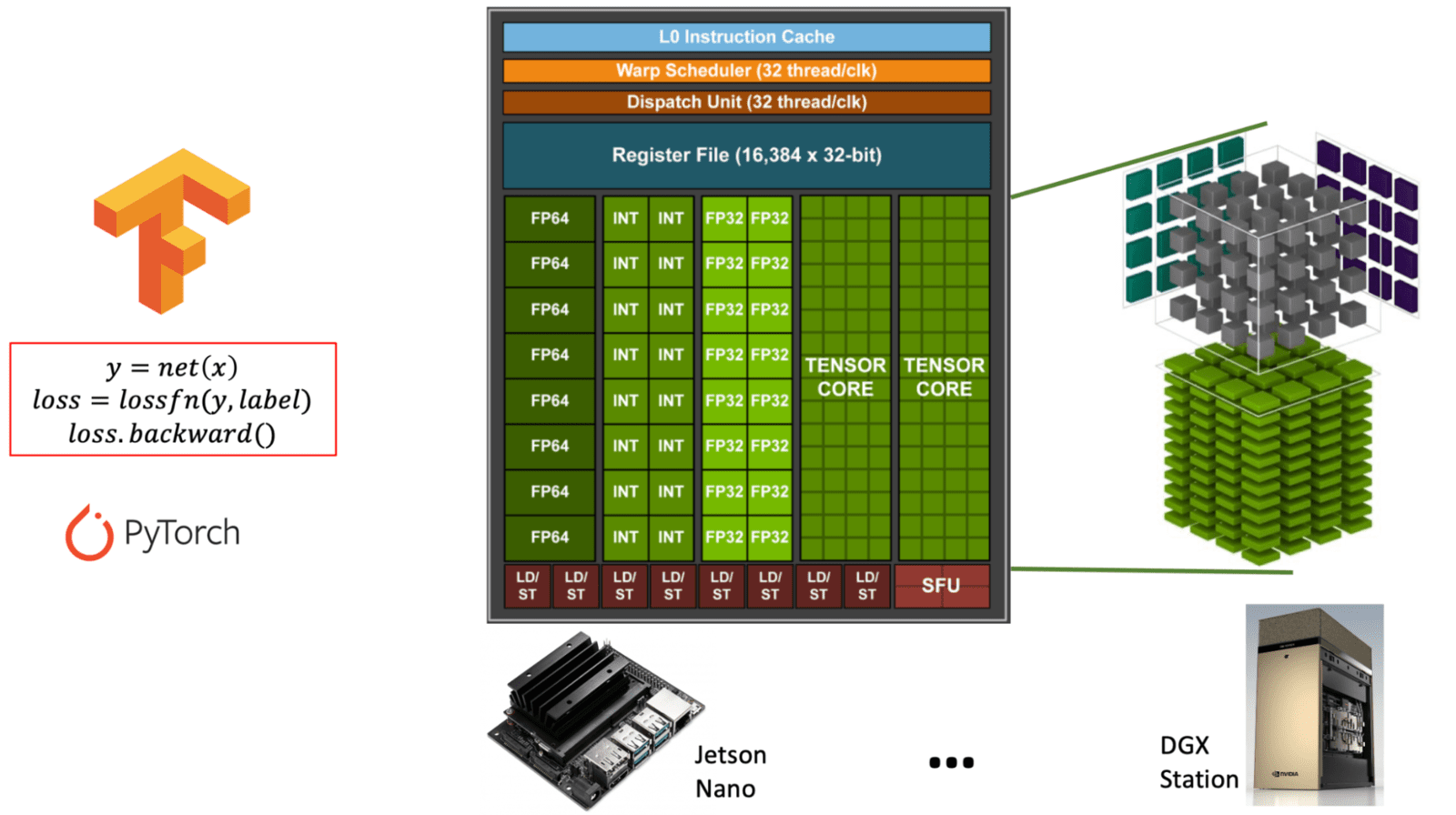
Diagram illustrating the difference between general-purpose CUDA cores and specialized Tensor cores within an NVIDIA GPU architecture. (learnopencv.com) - FP16/INT8 Support: Mixed precision training can significantly speed up computations while reducing memory usage.
** Table: Comparison of CUDA Cores vs. Tensor Cores in NVIDIA GPUs. This table explains the purpose, function, and usage of CUDA cores versus Tensor Cores, which are both essential for different types of GPU workloads, especially in AI and deep learning. **
| Feature | CUDA Cores | Tensor Cores |
|---|---|---|
| Purpose | General-purpose computation | Specialized for matrix operations (tensor math) |
| Primary Use | Graphics, physics, and standard parallel tasks | Deep learning tasks (training/inference) |
| Operations | FP32, FP64, INT, general arithmetic | Matrix multiply-accumulate (e.g., FP16, BF16, INT8) |
| Precision Support | FP32 (single), FP64 (double), INT | FP16, BF16, INT8, TensorFloat-32 (TF32), FP8 |
| Performance | Moderate performance for all-purpose tasks | Extremely high performance for matrix-heavy tasks |
| Software Interface | CUDA programming model | Accessed via libraries like cuDNN, TensorRT, or frameworks (e.g., PyTorch, TensorFlow) |
| Availability | Present in all NVIDIA GPUs | Present only in newer architectures (Volta and later) |
| AI Optimization | Limited | Highly optimized for AI workloads (up to 10x+ faster) |
3. Inter-GPU Communication
- NVLink: If running multi-GPU setups, NVLink provides significantly faster GPU-to-GPU communication than PCIe.
NVLink is a high-speed interconnect technology developed by NVIDIA to enable fast communication between GPUs (and sometimes between GPUs and CPUs). It addresses the limitations of traditional PCIe (Peripheral Component Interconnect Express) by offering significantly higher bandwidth and lower latency.
** Table: Overview of NVLink Bridge and Its Purpose. This table outlines the function, benefits, and key specifications of NVLink in the context of GPU-based computing, especially for AI and high-performance workloads. **
| Feature | NVLink |
|---|---|
| Developer | NVIDIA |
| Purpose | Enables fast, direct communication between multiple GPUs |
| Bandwidth | Up to 600 GB/s total in recent versions (e.g., NVLink 4.0) |
| Compared to PCIe | Much faster (PCIe 4.0: ~64 GB/s total) |
| Latency | Lower than PCIe; improves multi-GPU efficiency |
| Use Cases | Deep learning (LLMs), scientific computing, rendering |
| How It Works | Uses an NVLink bridge (hardware connector) to link GPUs |
| Supported GPUs | High-end NVIDIA GPUs (e.g., A100, H100, RTX 3090 with limits) |
| Software | Works with CUDA-aware applications and frameworks |
| Scalability | Allows multiple GPUs to behave more like a single large GPU |
Why NVLink Matters for LLMs and AI
- Model Parallelism: Large models (e.g., GPT-style LLMs) are too big for a single GPU. NVLink lets GPUs share memory and workload efficiently.
- Faster Training and Inference: Reduces communication bottlenecks, boosting performance in multi-GPU systems.
- Unified Memory Access: Makes data transfer between GPUs nearly seamless compared to PCIe, improving synchronization and throughput.
- Multi-Card Training: For distributed training across multiple GPUs, communication bandwidth becomes crucial.
Summary Table: Importance of Inter-GPU Communication in Distributed Training
( Table: Role of Inter-GPU Communication in Distributed Training. This table outlines where fast GPU-to-GPU communication is required and why it's critical for scalable, efficient training of deep learning models. )
| Distributed Training Task | Why Inter-GPU Communication Matters |
|---|---|
| Gradient synchronization | Ensures consistency and convergence in data-parallel setups |
| Model sharding | Enables seamless data flow in model-parallel architectures |
| Parameter updates | Keeps model weights in sync across GPUs |
| Scalability | Allows efficient use of additional GPUs or nodes |
| Performance | Reduces training time and maximizes hardware utilization |
4. Power Consumption and Cooling
- TDP (Thermal Design Power): Higher performance GPUs require more power and generate more heat.
- Cooling Solutions: Ensure your cooling system can handle the heat output of multiple high-performance GPUs.
Popular GPU Options Compared
** Table: Feature Comparison of NVIDIA GPUs for Deep Learning. This table compares the key specifications and capabilities of RTX 4090, RTX A6000, and RTX 6000 Ada, highlighting their strengths for deep learning workloads. **
| Feature | RTX 4090 | RTX A6000 | RTX 6000 Ada |
|---|---|---|---|
| Architecture | Ada Lovelace | Ampere | Ada Lovelace |
| Release Year | 2022 | 2020 | 2022 |
| GPU Memory (VRAM) | 24 GB GDDR6X | 48 GB GDDR6 ECC | 48 GB GDDR6 ECC |
| FP32 Performance | ~83 TFLOPS | ~38.7 TFLOPS | ~91.1 TFLOPS |
| Tensor Performance | ~330 TFLOPS (FP16, sparsity enabled) | ~312 TFLOPS (FP16, sparsity) | ~1457 TFLOPS (FP8, sparsity) |
| Tensor Core Support | 4th Gen (with FP8) | 3rd Gen | 4th Gen (with FP8 support) |
| NVLink Support | ❌ (No NVLink) | ✅ (2-way NVLink) | ✅ (2-way NVLink) |
| Power Consumption (TDP) | 450W | 300W | 300W |
| Form Factor | Consumer (2-slot) | Workstation (2-slot) | Workstation (2-slot) |
| ECC Memory Support | ❌ | ✅ | ✅ |
| Target Market | Enthusiast / Prosumer | Professional / Data Science | Enterprise / AI Workstation |
| MSRP (approx.) | $1,599 USD | $4,650 USD | ~$6,800 USD (varies by vendor) |
RTX 4090
- Architecture: Ada Lovelace
- CUDA Cores: 16,384
- Memory: 24GB GDDR6X
- Advantages: Highest performance-to-price ratio, excellent for single GPU workloads
- Limitations: No NVLink support, less memory than professional options
- Best for: Single-GPU training of medium-sized models, researchers with budget constraints
RTX A6000
- Architecture: Ampere
- CUDA Cores: 10,752
- Memory: 48GB GDDR6
- Advantages: Large memory capacity, NVLink support, professional-grade stability
- Limitations: Lower raw performance than newer cards
- Best for: Memory-intensive workloads, multi-GPU setups requiring NVLink
RTX 6000 Ada
- Architecture: Ada Lovelace
- CUDA Cores: 18,176
- Memory: 48GB GDDR6
- Advantages: Combines latest architecture with large memory and NVLink
- Limitations: Higher price point
- Best for: No-compromise setups where budget isn't a primary concern
Specialized Hardware Options
SXM Form Factor GPUs
** Table: Comparison of SXM vs PCIe Form Factors for GPUs. This table outlines the key differences and advantages of SXM over standard PCIe for deep learning, HPC, and data center applications. **
| Feature | SXM Form Factor | PCIe Form Factor |
|---|---|---|
| Connection Type | Direct socket interface (not via PCIe slot) | Plugged into PCIe slots |
| Power Delivery | Up to 700W+ per GPU | Typically limited to 300–450W |
| Thermal Design | Optimized cooling via custom heat sinks, liquid cooling options | Air-cooled with standard fans |
| Bandwidth/Latency | Supports NVLink with higher bandwidth and lower latency | Limited to PCIe bus speed |
| GPU Interconnect | High-bandwidth NVLink mesh between multiple GPUs | Lower-bandwidth peer-to-peer over PCIe |
| Size and Integration | Designed for dense server environments (e.g., NVIDIA HGX) | Fits in workstations or standard server racks |
| Performance Scalability | Excellent for multi-GPU configurations | Limited by PCIe bus and power constraints |
| Target Use Case | Data centers, AI training, HPC, cloud platforms | Desktop, workstation, light enterprise workloads |
- Options: V100, A100, H100 (with SXM2/SXM4/SXM5 connectors)
- Advantages: Higher power limits and bandwidth than PCIe versions
- Used in: High-end server platforms like NVIDIA DGX systems
Multi-Node Solutions
- Server platforms supporting 4-8 GPUs per node
- Examples: Dell C4140, Inspur 5288M5, GIGABYTE T181-G20
Decision Framework
- Identify your memory requirements first
- If your models won't fit in memory, performance becomes irrelevant ** Table: Understanding the Out-Of-Memory (OOM) Error in Deep Learning. This table explains what causes OOM errors, why they occur, and how GPU memory limits affect model training and inference. **
| Aspect | Explanation |
|---|---|
| What is OOM? | "Out Of Memory" error—occurs when a model or batch cannot fit in GPU VRAM. |
| Root Cause | Model weights, activations, and data exceed available GPU memory. |
| When It Happens | During model initialization, forward pass, backpropagation, or large batch loads. |
| Affected Components | Model parameters, optimizer states, activation maps, gradients. |
| GPU Memory (VRAM) | Finite resource that determines how large or complex a model can be. |
| First Check | Always compare model size + batch requirements against available VRAM. |
| Typical Triggers | - Model too large - Batch size too high - Mixed precision not used - Memory leak |
| Mitigation Strategies | - Reduce model size - Decrease batch size - Use gradient checkpointing - Apply mixed precision (FP16/8) - Use larger or multiple GPUs |
-
Determine your communication needs
- Multi-GPU training? Need NVLink? Or is PCIe sufficient?
-
Match to your budget
- For maximum price/performance: RTX 4090
- For memory-sensitive workloads with moderate budget: A6000
- For cutting-edge performance with large memory: RTX 6000 Ada
-
Consider long-term research trajectory
- For evolving research needs with potentially larger models: Choose higher memory options
Practical Deployment Tips
- When purchasing for academic research, ensure vendors can provide proper invoices for reimbursement
- Consider heterogeneous setups if different workloads are anticipated
- For multi-card systems, specify cards with
CUDA_VISIBLE_DEVICESwhen running experiments ** Table: Role ofCUDA_VISIBLE_DEVICESin Multi-GPU Management. This table shows how the variable works, why it’s useful, and scenarios where it improves GPU allocation and efficiency. **
| Aspect | Description |
|---|---|
| Function | Controls which GPUs are visible to a process |
| Syntax Example | CUDA_VISIBLE_DEVICES=0,1 python train.py — Only uses GPU 0 and 1 |
| Device Remapping | Internally remaps listed devices to logical IDs (e.g., 0 becomes cuda:0) |
| Isolation | Prevents overlap between concurrent jobs or users on shared GPU servers |
| Performance Optimization | Allows fine-tuned GPU assignment for load balancing |
| Distributed Training | Essential for assigning correct GPUs per node or worker |
| Debugging/Testing | Useful for testing code on a specific GPU or avoiding faulty ones |
| Dynamic GPU Use | Enables scripts to run on different sets of GPUs without code modification |
- Test your workloads thoroughly to determine actual memory requirements before purchase
By carefully evaluating these factors against your specific research needs and budgetary constraints, you can select the most appropriate GPU solution for your deep learning and LLM development environment.