
ByteDance Unveils Seed 1.5-VL: A Game-Changing Vision-Language AI Model Rivaling Gemini Pro 2.5
In a major leap forward for multimodal artificial intelligence, ByteDance’s Seed Team has released its latest vision-language large model, Seed 1.5-VL, marking a significant milestone in the global AI race. Designed with only 20 billion activated parameters, Seed 1.5-VL delivers performance comparable to Google's Gemini 2.5 Pro, setting state-of-the-art (SOTA) benchmarks across a broad spectrum of real-world visual and interactive tasks—all with substantially reduced inference costs.
🚀 What Happened?
On May 15, 2025, ByteDance officially launched Seed 1.5-VL, the latest evolution in its Seed series of multimodal AI models. Pretrained on over 3 trillion tokens of high-quality multimodal data—including text, images, and videos—Seed 1.5-VL combines advanced visual reasoning, image understanding, GUI interaction, and video analysis into a single, streamlined architecture.
Unlike bloated AI systems, Seed 1.5-VL relies on a Mixture of Experts (MoE) architecture, activating only a subset of its total 20B parameters for each task. This dramatically improves computational efficiency, making it ideal for real-time, interactive AI applications across desktop, mobile, and embedded environments.
Despite its relatively compact size, Seed 1.5-VL delivered SOTA results in 38 of 60 public evaluation benchmarks, including:
- 14 of 19 video understanding benchmarks
- 3 of 7 GUI agent tasks
In tests, it excelled at complex reasoning, optical character recognition (OCR), image interpretation, open-vocabulary detection, and security video analysis.
Seed 1.5-VL is now publicly available for testing via Volcano Engine’s API and the open-source community on Hugging Face and GitHub.
📌 Key Takeaways
- Multimodal Mastery: Handles images, video, text, and GUI tasks with human-level understanding.
- Efficiency First: Only 20B active parameters, offering comparable results to Google Gemini 2.5 Pro with lower costs.
- SOTA Achievements: Leads in 38 of 60 public benchmarks, especially in video and GUI tasks.
- Practical Applications: Already tested in OCR, surveillance analysis, celebrity recognition, and metaphorical image interpretation.
- Open Access: Live API on Volcano Engine, technical paper on arXiv, and code on GitHub.
🔍 Deep Analysis
Architecture & Innovations
Seed 1.5-VL is built on three major modules:
- SeedViT Visual Encoder: A 532M parameter encoder that extracts rich features from images and video frames.
- MLP Adapter: Bridges the visual encoder and language model by translating image/video features into multimodal tokens.
- Large Language Model: A 20B parameter MoE-based LLM optimized for inference efficiency.
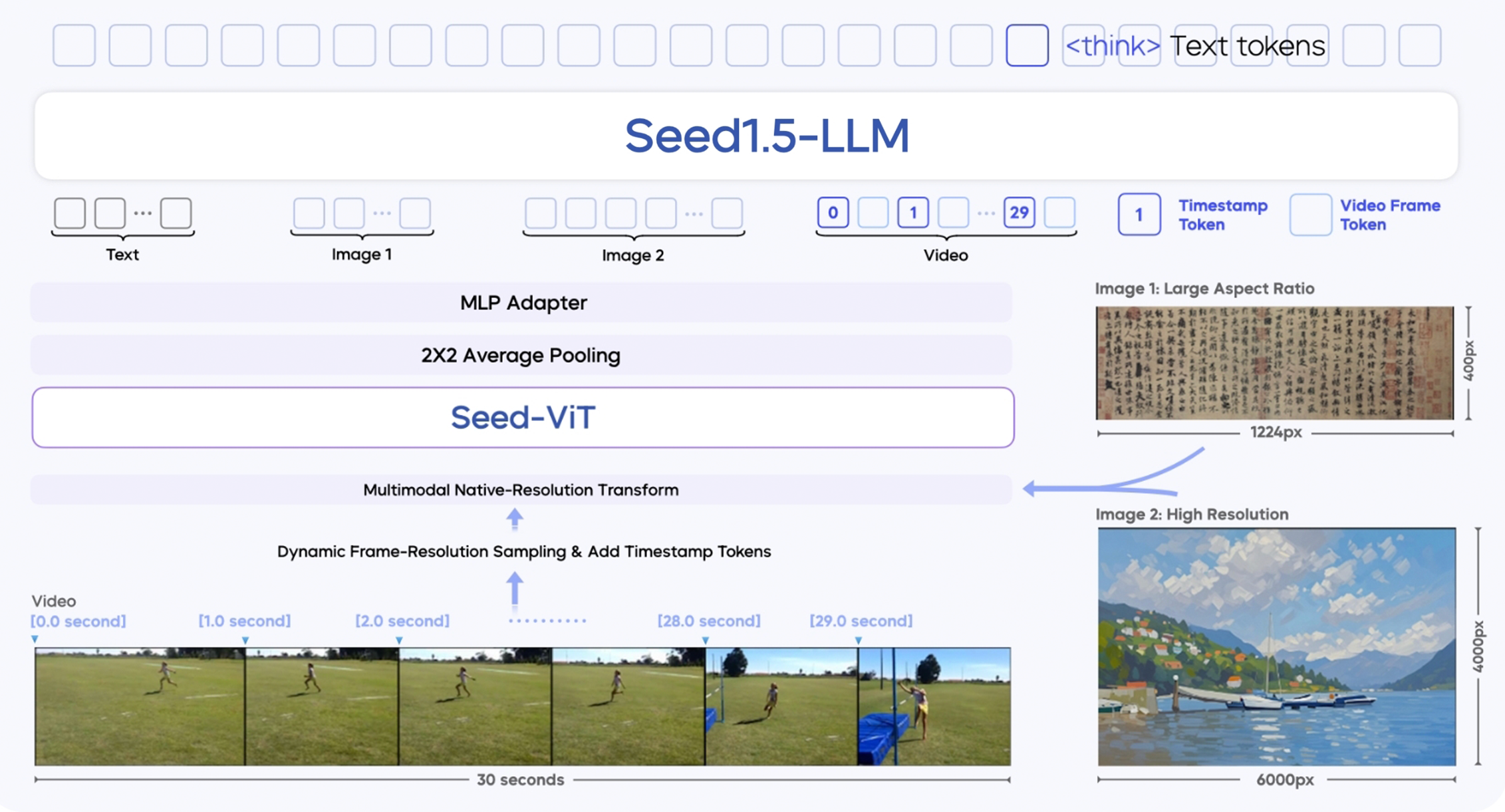
It introduces several technical innovations:
- Multi-resolution input support: Maintains image quality and precision.
- Dynamic frame-resolution sampling: Improves video understanding by selecting frames based on motion complexity.
- Temporal enhancement via timestamp tokens: Better tracks object sequences and causality in videos.
- Training on 3T+ multimodal tokens: Improves generalization across domains.
- Post-training refinements: Includes rejection sampling and online reinforcement learning to fine-tune response quality.
Strengths
Seed 1.5-VL shines in:
- Visual Question Answering (VQA) and chart interpretation
- GUI automation tasks, including gaming and app control
- Interactive reasoning in open-ended visual environments
- Real-world applications, such as celebrity identification, surveillance, and metaphor understanding
It’s praised for real-world robustness, something many academic models lack. Several reviewers even labeled it a "non-standard powerhouse" capable of competing with OpenAI’s o4 and Google’s Gemini.

Limitations
Despite its strengths, Seed 1.5-VL isn’t flawless:
- Fine-grained visual challenges: Struggles with object counting under occlusion, color similarity, or irregular arrangements.
- Complex spatial reasoning: Tasks like navigating mazes or solving sliding puzzles may yield incomplete results.
- Temporal inference: Difficulties arise when tracking action sequences across frames.
These are areas ByteDance acknowledges and is likely targeting in future iterations.
Competitive Context
Seed 1.5-VL launches amid an AI arms race:
- Google’s Gemini 2.5 Pro (May 6, 2025) dominates multimodal leaderboards (LMArena).
- OpenAI’s o3 and o4-mini (April 17, 2025) push multimodal tool use and reinforcement learning.
- Domestic competitors like Tencent and Doubao have enhanced image and voice capabilities.
Investment analysts are bullish: Agent models and multimodal capabilities are seen as key drivers of next-gen AI applications, particularly in enterprise software, ERP, OA, coding assistants, and office tools.
💡 Did You Know?
- Seed 1.5-VL can detect suspicious behavior in surveillance videos—an advanced real-world use case few models tackle effectively.
- It’s one of the few models capable of reading metaphorical imagery and explaining abstract relationships within them.
- Only 3 models globally (Gemini Pro 2.5, OpenAI o4, Seed 1.5-VL) are currently capable of real-time, interactive, cross-modal GUI control.
- ByteDance managed to rival Gemini Pro's performance using far fewer parameters, showcasing elite model compression and optimization skills.
- Seed 1.5-VL uses a native resolution-preserving transformation that avoids quality degradation common in traditional vision encoders.
Final Thoughts
Seed 1.5-VL marks a major milestone for ByteDance in establishing itself as a global leader in AI research, particularly in multimodal foundation models. With unmatched performance efficiency, robust real-world capability, and SOTA achievements in key benchmarks, it’s not just keeping up with the likes of Google and OpenAI—it’s competing head-on.
As AI adoption deepens across industries, models like Seed 1.5-VL will be at the forefront—shaping intelligent agents, powering automation, and redefining what machines can perceive, understand, and do.
CTOL Editor Ken: I highly recommend checking out the examples on ByteDance’s official Seed 1.5-VL page — they’re truly impressive.