
China’s GLM-4.6 Takes Aim at Silicon Valley’s AI Coding Edge—at a Fraction of the Cost
New model rivals Claude Sonnet 4 in real-world coding while cutting token use by 30%, giving China’s AI a shot at the global developer market.
China’s AI industry has thrown down a bold challenge. Zhipu, one of the country’s most ambitious AI companies, has just released GLM-4.6, a coding-focused model that, according to industry evaluations, matches Anthropic’s Claude Sonnet 4 in everyday programming tasks. The kicker? It does so while slashing costs by as much as 85%.
This launch comes in the middle of a crowded September rollout season, which already saw OpenAI’s GPT-5 Codex, Anthropic’s Claude Sonnet 4.5, and DeepSeek’s V3.2 hit the market. Unlike earlier battles that revolved around showing off benchmark scores, the race is now shifting toward something developers actually care about: affordable tools that get the job done.
![]()
Performance That Turns Heads
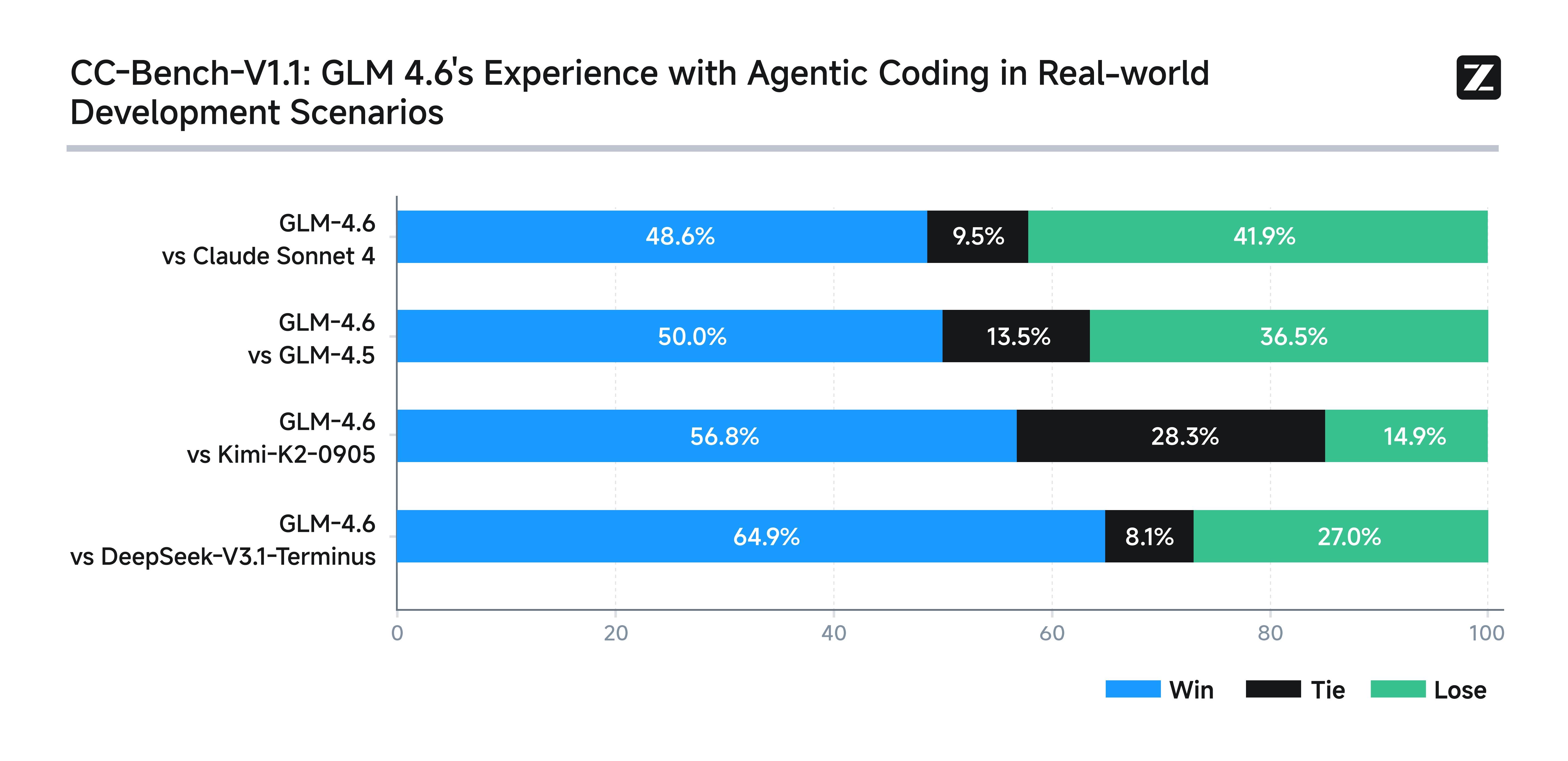
To test GLM-4.6, Zhipu set up 74 real-world coding challenges inside the Claude Code development environment. They then made the results public for verification on Hugging Face. The outcome surprised many: GLM-4.6 didn’t just beat Claude Sonnet 4 in several tasks, it also left all other Chinese competitors in the dust.
The challenges weren’t just dry academic benchmarks. Instead, they mimicked real developer headaches—things like building user interfaces, automating document processing, and creating data-heavy dashboards.
One standout test asked the model to compress a 64-page OpenAI research paper into a clean, one-page HTML infographic. Evaluators called the result “solid and well-structured.” It wasn’t as visually polished as Claude Sonnet 4.5’s output, but it beat models that cost many times more.
In another test, the model built a “Golden Week 2024 Tourism” data dashboard, complete with animations and dense graphics. Independent reviewers said GLM-4.6’s performance was on par with Claude Sonnet 4.5—a major achievement for any business that relies on sleek, functional dashboards.
Still, not everything was flawless. On SWE-bench Verified, a widely used coding benchmark, GLM-4.6 scored 68%, tying with DeepSeek-V3.2 but falling short of Claude Sonnet 4.5’s 77.2%.
Efficiency: The Secret Weapon
Where GLM-4.6 really shines is efficiency. It consumes about 30% fewer tokens than its predecessor, GLM-4.5. For reasoning tasks, the drop is even sharper: from 16,000 tokens down to just 9,000. That makes it the leanest Chinese reasoning model on the market.
Response times hover around 35 seconds—fast enough to place it among the quicker “second-tier” models.
As one engineering team member from CTOL.digital put it, “Developers don’t just want leaderboard champions anymore. They want models that handle real conversations, work with tools, and don’t burn through budgets.” GLM-4.6 seems to check those boxes.
A Price That Disrupts the Market
Efficiency means savings, and Zhipu is passing those along. Its GLM Coding Plan now starts at just 20 yuan—about three dollars—per month. That’s roughly one-seventh the cost of rivals. The plan covers “tens to hundreds of billions” of tokens each month, an allowance generous enough for most full-time developers.
On top of that, the subscription comes with vision recognition, search capabilities, and plug-and-play integration with tools like Claude Code, Roo Code, and Cline. For developers, the value proposition is simple: near-Claude 4 performance for pocket change.
Technical Upgrades and Tradeoffs
Zhipu didn’t just tweak pricing. GLM-4.6 stretches its context window from 128,000 tokens to 200,000, beating DeepSeek-V3.2’s 128,000. That lets it handle sprawling codebases or lengthy documentation in one go.
The model also shows stronger instruction-following, better arithmetic, and cleaner language output compared to earlier versions. But there are caveats. Syntax errors jumped to 13% across various programming languages, compared with just 5.5% in GLM-4.5. Developers who work in Go will notice this more than most.
There’s another quirk too: in long, complex reasoning tasks, GLM-4.6 sometimes quits early instead of brute-forcing its way to an answer. Reviewers called this a “concession tendency”—likely the price of its aggressive token optimization.
A Bigger Picture: Chip Sovereignty
Beneath the surface lies something with even greater strategic weight: chip independence. GLM-4.6 is the first production model to run FP8+Int4 mixed-precision inference on Cambricon chips. It also runs natively in FP8 on Moore Threads hardware using vLLM.
If these optimizations hold up, Chinese companies may finally loosen their reliance on NVIDIA GPUs—a key vulnerability given U.S. export restrictions. As CTOL.digital engineering team summed it up: “If training and inference both run smoothly on domestic chips, China builds a more autonomous AI stack.”
Rivalry Heats Up
The September wave of model releases highlights just how cutthroat the AI coding race has become. DeepSeek-V3.2 slashed its API prices by more than half. OpenAI’s GPT-5 Codex introduced “thinking” token trimming to lower costs. Anthropic’s Claude Sonnet 4.5 pushed ahead in complex reasoning.
Chinese firms, once dismissed as followers, are now innovating in ways that catch global attention. GLM-4.6’s mix of efficiency, chip integration, and low pricing is no accident—it’s part of a clear strategy to win over developers worldwide.
The model is already live: international users can find it at z.ai, Chinese users at bigmodel.cn, and open-source versions are hitting Hugging Face and ModelScope. Consumer chat apps and enterprise APIs are rolling it out as well.
What Developers Are Saying
Hands-on feedback has been promising. Developers report smoother front-end generation, fewer stalls, and quick recreation of older projects in modern frameworks like Vue 3. Some even built full tool-using agents that scrape data and generate local documentation without hiccups.
In front-end scenarios, GLM-4.6 often matches or even outperforms Claude 4. Still, Claude Sonnet 4.5 keeps its edge in heavy-duty reasoning and long-document tasks.
The Bottom Line
In today’s AI landscape, raw power is no longer the only story. Deployment strategy, efficiency, and cost matter just as much. GLM-4.6 balances all three. It isn’t the absolute top performer, but it’s close enough in most cases—and far cheaper.
For many developers, that combination will be irresistible. One analyst called it “the most usable domestic coding model” and a credible challenger to Western offerings.
Whether this marks the start of long-term Chinese competitiveness or just a temporary edge remains to be seen. But one thing is clear: in October 2025, GLM-4.6 has changed the conversation about what developers should expect to pay for frontier-level AI coding.