
The Conversational Blind Spot: Inside Claude Haiku 4.5’s Speed–Intelligence Tradeoff
Anthropic just dropped its newest “small” AI model, Claude Haiku 4.5, and it comes with a bold promise—frontier-level coding power at lightning speed and a fraction of the usual price. On paper, it looks like a dream: twice as fast and one-third the cost of models released barely five months ago. But behind the headlines, early enterprise users are discovering a flaw that could reshape how companies deploy AI assistants.
Haiku 4.5 writes code like a pro. The problem? It doesn’t always understand what you want it to build.
The engineering team at CTOL.digital, one of the first to use the model in real environments, put it bluntly: “The coding is fine, but it is really hard to converse and understand business requirements or normal day-to-day conversations.” Their feedback, echoed by multiple enterprise users, highlights a growing industry dilemma—when speed and cost optimization overpower comprehension, execution suffers.
The Economics of “Almost Frontier” AI
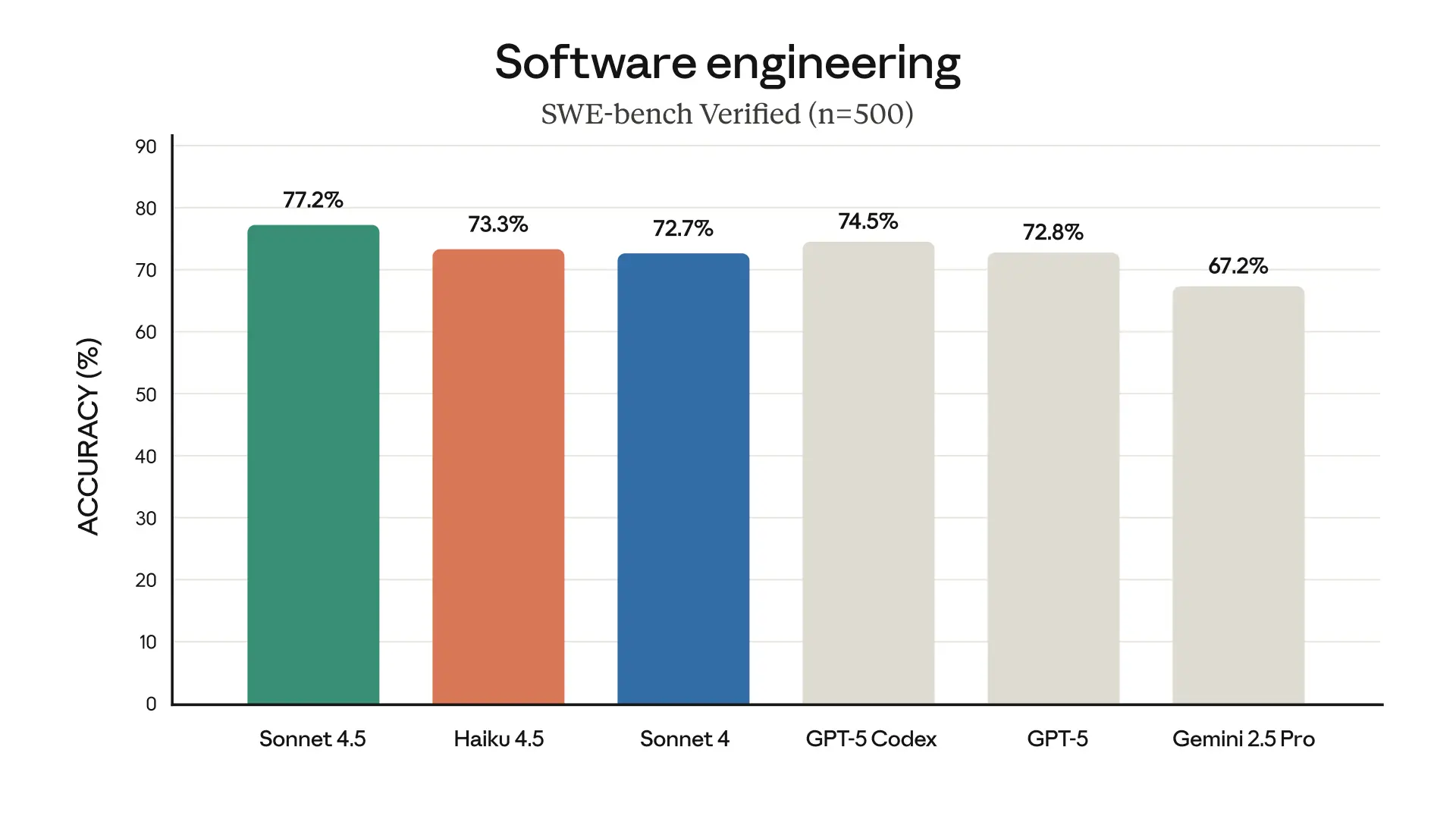
Claude Haiku 4.5 hits hard in the value department. It rivals Claude Sonnet 4—a premium model from earlier this year—but at a fraction of the price. On SWE-bench Verified, one of the most demanding coding benchmarks, Haiku hits 73.3% accuracy and processes requests more than twice as fast.
The pricing is the real shocker: $1 per million input tokens, $5 per million output tokens. That’s the sweet spot where enterprises actually scale usage across departments and production systems.
Anthropic didn’t just launch a product—it executed a distribution blitz. Haiku 4.5 is already available on AWS, Google Cloud, and even previewed inside GitHub Copilot. The goal is clear: make Haiku 4.5 the default engine for the massive “middle tier” of AI tasks powering chatbots, coding assistants, and internal automations.
One technical analyst summed it up: “This re-prices ‘small-but-smart’ across the board. Expect rivals to react fast.”
What Engineering Teams Are Really Saying
Speed and affordability don’t matter if the system misreads your intent. CTOL’s testing reveals a pattern: Haiku 4.5 excels at raw implementation but struggles with the human-to-AI conversation that leads up to it.
On the tech side, it’s impressive: “Very fast and responsive; near-Sonnet-level coding quality,” their internal notes say. In multi-agent setups—where one model plans and others execute—Haiku 4.5 shines as a worker.
But ask it to gather requirements, talk through ideas, or handle the messy back-and-forth of real software development, and friction appears. Many testers described a “rocky start” where the model feels “a total pain” until they force it into coding mode.
This creates an odd paradox: the cheaper model ends up requiring more communication skill from the user. Instead of AI adapting to humans, humans must adapt to AI.
The Benchmark Mirage
Anthropic is transparent about its testing process—and that transparency reveals a lot.
Their benchmarks used:
- Heavily engineered prompts
- Tool use encouraged “more than 100 times”
- Massive “thinking budgets” of up to 128,000 tokens
- Carefully tuned agent frameworks
In other words, great science, but real-world apps won’t always provide that level of scaffolding. One analyst warned, “Expect a gap versus the blog numbers.”
CTOL’s experience confirms it. Under perfect prompting, Haiku 4.5 shines. Under natural, messy conversation, it falters. And that matters, because the whole point of AI assistants is to remove friction, not add rules for how to talk to a machine.
The Planner–Executor Future
Anthropic seems to know this. Instead of pretending Haiku is a one-size-fits-all solution, the company positions it as part of a team.
Sonnet 4.5 plans. Haiku 4.5 executes.
“Sonnet breaks down complex problems into steps, then orchestrates multiple Haiku 4.5s to complete tasks in parallel,” the company explains.
CTOL agrees. They call Haiku “ideal as a fast executor under a Sonnet planner.” Give it clear instructions, and it flies. Ask it to infer structure from conversation, and it stumbles.
This planner-executor model may become the new AI architecture: expensive models handle understanding, cheap models handle work.
A Smart Tradeoff… or a Strategic Trap?
Haiku’s weakness could actually be intentional. By optimizing for execution rather than comprehension, Anthropic built a model perfectly suited for a specific role: the reliable worker that doesn’t need to know why, only what.
There’s economic logic here. If 80% of AI workload involves executing well-defined subtasks, making that cheap and fast saves money. The remaining 20%—the planning, the reasoning, the nuance—can be handled by premium models.
Plus, Haiku 4.5 has an ASL-2 safety rating, meaning fewer restrictions and wider deployment. Higher-tier models remain locked behind stricter controls.
But this approach forces enterprises into multi-model setups. They save on execution costs but must pay for smarter models to handle the front end. That’s a tradeoff many will accept—but it also tightens reliance on specific vendors.
What Enterprises Need to Know
Based on what early adopters discovered, here’s what smart teams are doing:
Don’t use Haiku 4.5 for customer conversations or requirements gathering. It’s not built for that.
Route tasks:
- Structured coding → Haiku
- Ambiguous requests → Sonnet or other high-level models
Expect benchmark performance to dip in production. Real-world input is messy. Budget for that gap.
One pleasant surprise: Haiku 4.5 is more open and cooperative than Haiku 3.5. Testers say it engages with content the previous version avoided—evidence Anthropic has improved alignment, even if conversational depth still lags.
The Industry’s Turning Point
Haiku 4.5 forces a bigger question: Are we moving toward AI that truly collaborates with humans—or toward specialized tools that require expert handling?
The conversational blind spot matters because it represents a step back from the original promise of large language models: that natural language becomes the universal interface. If we must “speak AI” to get good results, have we really advanced?
Some enterprises already feel the tension. One engineer on Reddit captured the mood: “Recognized as cheaper than Sonnet, but criticized as overpriced vs OpenAI/Gemini budget tiers and ultra-low-cost models.”
The next few months will decide the direction. Will planner–executor become the standard, or will someone crack the trifecta: fast, cheap, and deeply conversational?
Until then, Haiku 4.5 delivers brilliant execution—just don’t expect it to fully understand what you mean without guidance. As CTOL’s team learned the hard way: speed is powerful, but comprehension is everything.
Anthropic declined to comment on specific feedback but pointed to the model’s technical documentation and system card for details on capabilities and limitations.
This article draws on internal testing notes, technical documentation, and interviews with enterprise users of Claude Haiku 4.5. Some sources requested anonymity to speak candidly about early-stage AI systems.